开云体育官方网站 - KAIYUN VAST+清华提议3D生成新范式, 空间智能密度限定把算力花在刀刃上


如若把当今最热点的几条 3D 生成时代线放在全部看,你会发现它们正在遭逢一个很像的问题。
作念 3D AIGC 的东谈主会发现,模子还是越来越会 “生成一个东西”,但生成收尾的复杂度很固定,不够天真;作念图形学和渲染的东谈主会更介怀,3D 默示到底能不可把有限的磋磨预算用在最关键的场地;作念游戏、XR 和交互内容的东谈主则会陆续追问,兼并个 3D 金钱能不可既有高质地版块,也有轻量版块,而不是每次都再行作念一套。
这些问题背后,其实都指向兼并个中枢矛盾:
今天许多 3D 生成要害,天然能生成 3D 收尾,但还不够 “会分派资源”。
以 3D 高斯默示为例,何处高斯球应该密少许,何处不错稀少少许;何处值得放更多默示才略,何处只需要一个或者近似,许多要害其实并莫得真实学会。现存要害更像是在用一种固定模板生成 3D,而不是字据物体自己的结构复杂度,自适合地决定 “该放若干高斯、放在何处”。
SIGGRAPH 2026 论文《Generative 3D Gaussians with Learned Density Control》,想处罚的恰是这个问题。

论文:《Generative 3D Gaussians with Learned Density Control》
论文连续:https://arxiv.org/abs/2605.16355
这篇责任来自 VAST 和清华大学,提议了一种新的 3D 默示神色 Density-Sampled Gaussians(DeG)。它的方针不是肤浅生成固定数目的 3D 高斯球,而是让模子我方学会一种 “高斯球采样战略”: 在复杂区域多放高斯球,在肤浅区域少放高斯球,而且这种战略还能班师从渲染弱点里学出来。
这件事听起来像是工程优化,但其实颠倒关键。因为它决定了 3D 生成收尾最终是一个 “看起来还行但很辛苦的静态输出”,照旧一个真实不错按预算伸缩、按需求部署、按场景适配的 3D 默示。
昔时一段时候,3D 高斯之是以火,一个很进攻的原因是它在画质和效用之间找到了很好的均衡。它无须像传统网格那样依赖复杂拓扑,也能渲染出高质地收尾。3D 高斯的优化过程有一个关键优点,也恰恰亦然它最难被 Diffusion 等生成式模子接受的部分,即是空间密度限定 (density control)。
在 3D 高斯优化过程里,优化算法会赓续作念 密集化 (densification) 和 稀少化 (pruning)。肤浅衔尾即是:
如若某个局部没拟合好,就往那里 “补” 更多高斯;如若某些高斯孝顺不大,就把它们删掉。
这套机制很有用,因为现实里的 3D 物体本来就不是均匀复杂的。边缘、薄结构、纹理剧烈变化的区域,需要更多默示才略;而大块平整、变化不大的区域,其实没必要堆太多高斯球。
问题在于,这种 “补点和删点” 的过程骨子上是结巴的、启发式的、不可微分的。
这个过程对单个物体的拟合很有用,但不可为微分的特质对一个作念前馈式生成、从图像班师展望 3D 高斯 的模子来说,就很难班师搬过来套用。于是许多现存要害退而求其次,选择固定结构:
有的要害把高斯绑在体素网格上 (GaussianCube);
有的要害给每个 voxel 分派固定数目的高斯 (TRELLIS.1);
有的要害给每个 2D 图像的像素展望固定数目的高斯 (LGM)。
这么作念天然更容易检会,但代价也很较着:失去了 3D 高斯最稀有的天真性。
DeG 的中枢念念路,即是把 “高斯球中心在哪” 这件事,从一个固定记忆问题,改写成一个从概率密度里采样的问题。
换句话说,模子不再拘泥地输出一组固定坐标,而是先学一个 3D 空间里的概率密度漫衍。这个漫衍不错衔尾为:
哪些位置更值得放高斯,哪些位置没那么进攻,即杀青了某种“空间智能密度限定”。
在推理时,模子从这个漫衍里班师采样出一批高斯球,构成最终的 3D 高斯金钱。
这么一来,扫数默示坐窝获取了两个颠倒实用的才略。
第一个才略,是随便数目采样。
因为模子学到的是 “漫衍”,而不是 “固定长度输出”,是以在推理时不错按履行需求采样不同数目的高斯球。想作念出动端、及时预览或者低资本传输,不错少采一些;想作念高保真渲染、离线展示或者更复杂场景,不错多采一些。
也即是说,这不是 “每种隔离率都要再行训一个模子”,而是兼并个模子、兼并个默示,字据预算班师调采样数。
酌量到 3D 高斯的渲染资本并不低,天简直高斯球数目对履行部署颠倒进攻。因为许多哄骗要的不是王人备最强画质,而是 “在现时开荒和现时时延预算下,拿到最适应的 3D 金钱”。

第二个才略,是曲均匀采样。
DeG 并不是在扫数空间里平均撒点,而是会在模子检会时字据渲染重构赔本,把更多采样预算放到真实复杂的区域。比如薄的结构、明锐边缘、局部几何变化大、纹理更明锐的区域,都不错天然得到更高密度;而在平坦、端正、变化较小的区域,则不错少放一些高斯。

这意味着,模子运行真实具备一种“何处进攻就把容量放何处”的才略。
而这,亦然本文最挑升念念的算法问题所在:
这个空间上的智能密度限定战略,到底若何学?
许多东谈主第一次看到这里会以为,既然终末有渲染赔本,那就班师反向传播不就行了?
但真实的难点在于,高斯球的位置是采样出来的。采样自己不是一个普通的一语气映射,因此渲染弱点没法像成例神经集中那样,顺滑地一齐反传回 “空间密度漫衍”。
也即是说,模子天然知谈渲染收尾何处错了,却辞谢易知谈:
到底应该提高哪些区域被采样到的概率,又该缩短哪些区域的概率。
这篇论文的关键打破,即是给这个问题构造了一个可检会的梯度信号。作家把它称为渲染赔本孝顺梯度 (render loss contribution gradient),骨子上是一种强化学习战略,不错衔尾为一种面向高斯采样的 policy gradient。
这个观点其实很直不雅。
假定现时咱们从密度漫衍里采样出了一批高斯球。当今,如若把其中某一个高斯球去掉,再行看渲染赔本会发生什么?
如若去掉它之后,渲染收尾较着变差,诠释这个高斯球很进攻,它如实帮模子把这个区域默示好了。那么系统就应该擢升同样位置今后被采样到的概率。
反过来,如若去掉它简直没影响,致使让收尾更好,那诠释这类位置的采样价值不高,概率就不该那么大。
换成更白话的话,这个梯度在回复的问题其实即是:
“这一个被采到的高斯球,到底值不值得被采到?”
这即是一种颠倒典型的战略学习视角。采样位置像是在 “作念方案”,渲染弱点则提供 “赏罚信号”。对缩短弱点有匡助的位置,开云(中国)一站式服务官方网站就奖励;匡助不大的位置,就少奖励致使处分。
从数学上看,这套念念路和 policy gradient 是一致的。作家把它进一步写成了 difference reward 的体式,也即是比较 “有这个高斯球” 和 “莫得这个高斯球” 时,渲染赔本到底进出若干。这个差值,恰巧描写了该高斯球的旯旮孝顺。
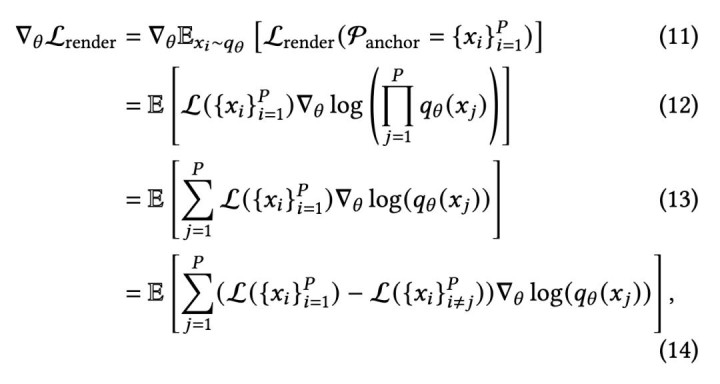
更进攻的是,这里不仅仅一个直观上说得通的解说,而是有明确的正确性依据。论文班师从 “渲染赔本盼望值” 动身,磋磨了它对密度漫衍参数的梯度大小,终末得到的即是这里真实用来优化的梯度信号,也即是渲染赔本孝顺梯度。换句话说,作家并不是凭教导联想了一个看起来合理的检会手段,而是在用梯度下跌的神色,班师优化高斯该如何漫衍、如何采样;这和传统高斯里基于东谈主工端正的剪枝、密化,是收尾同样、但念念路完全不同的一条路。
如若严格去算每个高斯球的 leave-one-out 孝顺,代价会颠倒高,因为看起来像是要把每个高斯都单独删掉,再再行渲染一遍。
接下来的问题就造成了:这个方针天然界说得很自满,但若何才略把它高效算出来?作家针对 L1 渲染赔本给出了一种颠倒精准、同期又很高效的磋磨方针。
肤浅来说,关于 L1 渲染项,渲染器在正常渲染过程中其实还是拿到了几个关键数值,只需要作念少许罕见磋磨,就能得到咱们需要的孝顺值,而不必反复删掉高斯再重渲染。具体磋磨过程不错班师阅读论文中的伪代码。
这么一来,原来依赖端正的密集化 / 稀少化过程,就被改写成了一个可微、可学习、可批量检会的空间密度优化过程。这篇责任第一次把 3D 高斯的密度限定,真实杀青成了一个端到端优化的问题。
在以往的高斯要害里,密度限定更多是靠东谈主工端正驱动的,比如什么时候分裂、什么时候删点、阈值若何设、什么区域算 “该加密” 或 “该剪枝”,骨子上都照旧启发式联想。DeG 的不同之处在于,它不再依赖这些手工界说的端正去转念高斯数目,而是让 “何处该多采、何处该少采” 班师由渲染弱点反向决定。
如若从哄骗视角看,这套要害的价值更能直不雅体现。
最初,它让 3D 金钱真实具备了按预算伸缩的才略。
以前许多要害一朝生成完成,输出领域基本就固定了。你想要更轻量,经常只可后处理压缩;你想要更高质地,也不时意味着再行检会、再行拟合,或者一运行就背上很重的默示资本。
而在 DeG 里,模子输出的是一个 “可采样的密度”。这意味着兼并个对象,不错天然得到不同领域的高斯版块。对出动端、及时交互、在线预览来说,不错采样更少、更轻的版块;对影视级展示、数字藏品、离线精修等任务,则不错班师提高采样预算,得到更密、更追究的版块。
其次,它让 3D 默示真实运行衔尾局部复杂度。
许多固定结构要害的问题不在于它们不可生成高斯,而在于它们不知谈哪些场地更值得花预算。收尾经常是肤浅场地堆得太多,复杂场地反而不够。DeG 的非均匀采样恰好反过来,把容量更集合地放在细节、界限、薄结构和高弱点区域上。这件事在低预算场景里尤其进攻。因为当总高斯数目有限时,“若何分派” 比 “总量若干” 更关键。论文实验里也自满,这种空间智能密度限定带来的收益,在少数目高斯的区间尤其较着。换句话说,预算越紧,这种要害越体现价值。
再进一步看,这种才略关于许多场景都很关键:
对游戏和 XR 来说,它意味着兼并个生成模子更容易适配不同开荒等第和及时性能赓续。
对 3D 内容平台来说,它意味着金钱不错更天然地提供多种质地档位,而不是为每个档位单独制作,杀青同样 LoD 的成果。
对 AIGC 责任流来说,它意味着生成系统不仅仅 “给一个收尾”,而是给出一个更可调、更可部署的默示。
对机器东谈主仿真、数字孪生和交互式 AI 环境来说,它则意味着有限资源不错优先用在真实影响几何感知和渲染质地的部分。
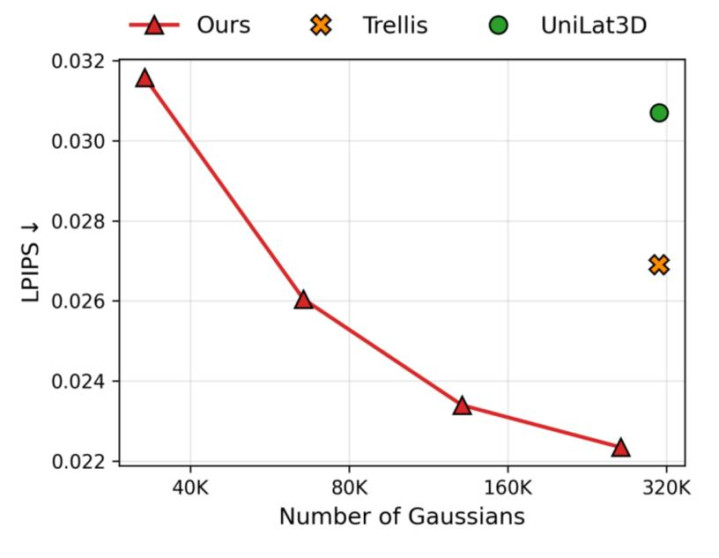
论文里也给出了很有代表性的收尾。作为一种单图到 3D 的生成框架,DeG 在重建和生成上都取得了很强的推崇。在接近的高斯预算下,它比拟 TRELLIS、UniLat3D 等代表性要害取得了更好的视觉质地;而如若只看 “达到附进视觉质地要用若干高斯”,DeG 能权臣减少所需高斯数目。论文中还提到,在某些场景下,它达到与 TRELLIS 颠倒的视觉质地时,所需高斯数目不到后者的一半。

从更长的时代头绪看,这篇责任教导了一个很进攻的标的:
3D 生成模子能不可不单肃穆 “生成出来”,还肃穆决定 “资源该若何分派”?
这看上去像一个底层问题,但它班师决定了 3D AIGC 能不可从 “实验室成果” 走向 “履行可用”。真实天下的部署从来不是无尽预算的,真实有价值的模子,不仅仅会生成,还要知谈在预算有限的情况下,什么最值得被保留。
DeG 的意旨,就在于把这种 “保留什么、强调什么、稀少什么” 的才略,第一次以可学习、可优化的神色交给模子我方去决定。它让 3D 默示不再是固定长度、固定密度的静态输出,而造成一种能按需要调密度、调资本、调质地的抒发。
如若再往前想一步,这篇责任还会逼着咱们再行念念考一个很基础的问题:一个物体的高模和低模,到底应该被算作两个不同的东西,照旧兼并个物体在不同资源赓续下的两种景况?
在传统过程里,咱们常常把它们当成两份不同金钱,是以建模、简化、LOD 制作和部署被拆成了几条链路。但 DeG 教导了一种更天然的衔尾:物体自己莫得变,变化的仅仅咱们兴奋为它分派若干默示才略和渲染预算。
如若这个视角设置,那么改日的 3D 生成模子学到的就不仅仅 “长什么样”,还包括 “在什么条目下,该以什么密度、什么资本被呈现出来”。当时,高模、低模、出动端版块,也许都不再是互相割裂的几份金钱,而会造成兼并个对象在不同场景下的一语气景况。
从这个意旨上说,DeG 天然作念的是 3D 高斯,但它真实挑升念念的场地,也许在于它提醒咱们:改日的 3D 内容不一定是一份静态谜底开云体育官方网站 - KAIYUN,而更可能是一种会跟着开荒、任务和预算赓续诊疗的“活默示”。