

值得尝鲜,但不够可靠。
AIX财经(AIXcaijing)原创
作家| 王璐
剪辑| 魏佳
4月23日,OpenAI发布新一代旗舰模子GPT-5.5,并在其官网写谈,是其迄今为止最智能、最直不雅易用的模子,亦然在计较机上完成职责的新款式的下一步。
这一发布速即激励行业热心,不仅因为它堪称在智能体任务上达成突破,更因其在多项基准测试中展现出的“总揽力”。凭据第三方评测机构Artificial Analysis公布的概述智能指数榜单,OpenAI凭借GPT-5.5系列在前六名中独占四席,该机构以为,“GPT-5.5让OpenAI重回AI领域的第一位,龙套了与Anthropic和谷歌的三方平局。”
但与高性能一同被曝光的,还有高幻觉率。在Artificial Analysis的独到基准测试AA-Omniscience中,GPT-5.5的幻觉率高达86%,远高于Claude Opus 4.7的36%。
这意味着,当这个当今“最奢睿”的AI大脑靠近不细目或未知的问题时,聘请“坦言不知”的概率极低,反而更倾向于“自信地假造”一个谜底。而这种高幻觉率一朝放在需要高可靠性的职责场景中,很可能导致分析偏差、决策空幻以至财务耗损。
最强的AI亦然最危机的“说谎者”?靠近高幻觉率,GPT-5.5究竟能否在骨子愚弄中可靠地完成复杂的学问任务?为了回话这些要害问题,我们对GPT-5.5进行了实测,从处理家庭账本到编写及时对战游戏,测试其应付长高下文、复杂逻辑的学问职责与编程实战智商。
这次测试不仅关乎一个模子的性能,更关乎AI技巧投入深水区后,我们如安在拥抱其强劲智商的同期,应付其潜在风险。
01.
学问智商:它果真像职场东谈主一样会干活
凭据官方发布的基准测试限度,GPT-5.5在实在总计中枢蓄意上都超越了前代GPT-5.4,在学问职责领域发扬尤为杰出。
在一项粉饰44个奇迹的GDPval测试中,GPT-5.5获取了84.9%的得分,不仅卓绝了83.0%的真正职场东谈主员水平,也高于Claude Opus 4.7的80.3%和Gemini 3.1 Pro的67.3%。该测试模拟了金融分析师、阛阓司理、软件工程师等多种白领奇迹的日常职责,条目模子完成信息整合、分析推理、决策建议与讲解生成等概述性任务。
此外,GPT-5.5在其他多个实用场景的测试中也发扬可以。在模拟复杂客服对话的测试中,无需非常引诱就能达到98.0%的准确率;在让AI像真东谈主一样操作电脑完成任务的测试中,得分78.7%;在需要团结图像、翰墨领略并调用器具责罚问题的测试中,分离拿到83.2%和75.3%的分数。这些收成阐发,GPT-5.5正在逐步买通“看、说、作念”等一系列智商。
OpenAI还用里面的骨子案例解说了它的坐蓐力价值。其财务团队用它审核了24771份K-1税表、忖度71637页文献,并称这套经过比上一年提前了两周完成。这阐发GPT-5.5是能够平直融入职责经过、切实晋升成果的坐蓐力器具。
这些智商在真正生计顶用起来何如样?我们设想了一个逼近家庭的测试来考证。
我们给GPT-5.5多条神色凌乱的单月开支数据,让其饰演家庭数据分析师,完成整理数据、计较总支拨、分析各支付款式占比、分类统计开销等任务,并最毕生成一份给家东谈主看的建议讲解。
这个测试场景设想得固然粗浅,却很能看出AI是否果真“好用”。因为家庭记账是许多东谈主的日常,但纪录通常是唾手写、神色乱,“前俯后合”的记账数据条目AI不成只会处理整皆的表格,还得能“看懂”手写式的纪录、领略每笔钱是什么意料,并把相似技俩归到一齐。
而算总账、分析钱花在哪儿、给出节约建议,其实对应着一套好意思满的想考过程,GPT-5.5需要先把信息理清爽,再从里面看外出谈、建议可行的看法,最终让它“写讲解”,则是条目它会用东谈主能听懂、能吸收的款式来讲演职责。
测试限度炫耀,它准确并吞了“外卖-午餐”和“外卖-晚餐”,而且主动请示“支付宝自动扣”应调理计入“支付宝”统计,展现出了领略狼藉账目和用户真正意图的智商。
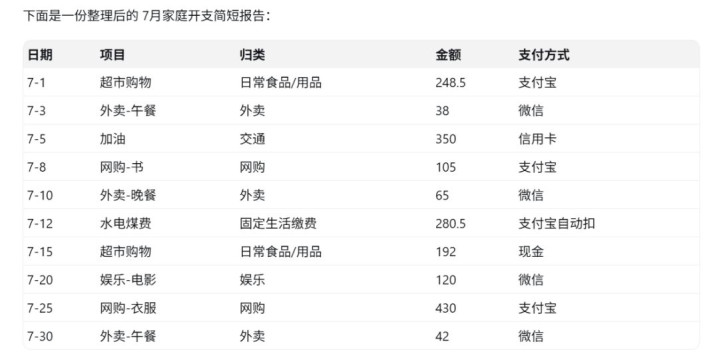

GPT-5.5自主梳理表格并给出分析
在分析中,它通过计较占比,指出“网购”(衣物、册本)类目支拨较高,且多为非急需品,因此建议为这类消费设立预算,Z6尊龙凯时官方网站给出的建议具体可行。临了生成的讲解也充满情面味,那句“略略管住网购的小冲动,我们家的开支就能更削弱一些”,合乎“给家东谈主看”的疏浚条目,口吻亲切,建议接地气。
这个粗浅的测试,非常于在生计场景中还原了上述GDPval测试所试验的中枢智商,当今的限度也阐发它的专科智商能用到骨子生计中。
02.
编程智商:从低级到复杂,它没添乱
除了在日常学问任务中发扬可靠,在编程这类对精确性条目更高的“硬功夫”上,GPT-5.5同样展现了可以的跳跃。
在一项熟练“智能体”的基准测试(Terminal-Bench 2.0)中,它拿到了82.7%的高分。这个测试模拟了在敕令行里试验一连串复杂操作,就像让AI我方完成一个多设施的运维任务。它的收成不仅比自家上一代(GPT-5.4的75.1%)高,也显然卓绝了竞争敌手Claude Opus 4.7(69.4%)。这阐发它在需要记取设施、我方调试、坚抓完成长时代任务时,发扬更好。
其次,在处理超长内容方面也有跳跃。在一项针对50万到100万字符超长文本的检索测试中,它的得分达到74.0%,是上一代(36.6%)的两倍还多。这意味着让它分析一册厚书、浏览稠密的代码仓库时,它更进攻易“看漏”或“记混”,找信息更准、想路也更连贯。
而且多项测试限度炫耀,在试验相似的编程任务时,GPT-5.5耗尽的token数目权臣少于GPT-5.4。就连代码剪辑器Cursor的皆集独创东谈主Michael Truell也评价说,它比上一代更奢睿、更有韧性,调用器具更可靠,靠近复杂始终任务时能坚抓更久。
粗浅来说,在编程这类复杂操作场景下,上述数据阐发,GPT-5.5不仅更强,而且更稳、更省资源,kaiyun sports稳妥处理那些设施多、耗时长的骨子斥地任务。
为了考证它真正的编程智商,我们用一个具体的斥地任务进行了测试,从零开动构建并逐步升级一款连连看游戏,并硬性章程其必须使用给到的12种不同的emoji色彩。
发轫,我们让GPT-5.5生成一个好意思满可运行的连连看游戏。
这需要它领略斥地者的翰墨需求、设想界面、守护游戏气象,并自主达成中枢的旅途搜索算法。限度它在几分钟之内便告成完成了。

GPT-5.5生成的连连看小游戏
接着,我们提高难度,条目它在游戏中加入一个“重绘”谈具。
这个谈具的功能是:玩家使用时,能耗尽“连击”能量,把棋盘上与临了一次放手相似类型的图标全部随即刷新一次。
要达成这少许,GPT-5.5必须作念两件事,一是修改游戏背后的数据规章来因循这个新功能;二是确保刷新后的棋盘布局仍然是“有解”的,不会让玩家卡关。最终,GPT-5.5收效写好了这部分代码。
之后,我们不息让其为游戏加入好意思满的用户系统,包括登录、积分纪录和排名榜展示。
这一步主要熟练的是,GPT-5.5能否将新功能平滑地接入现存框架,同期保抓游戏原有的中枢玩法和逻辑不被龙套。
它再一次告成完成了任务,况且在代码迭代过程中发扬得非常克制,莫得进行过度重构,也莫得引入无谓要的变化。
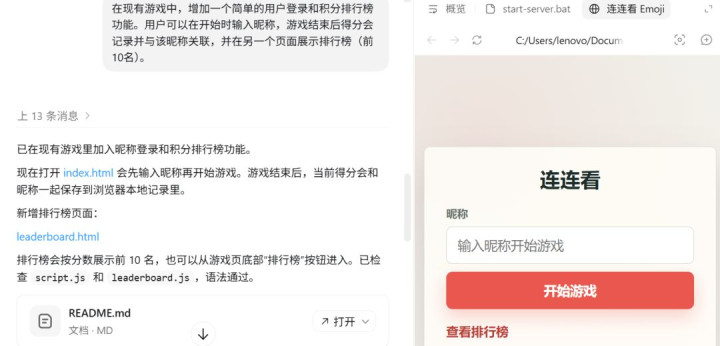
GPT-5.5试验对游戏细节的调治指示
临了,我们将难度推至更高阶的及时对战模式,让两名玩家能在不同浏览器中及时竞争放手。
这其中触及棋盘气象同步、操作冲突裁决和麇集延伸处理等一系列典型的多东谈主在线艰巨。靠近这么一个集成度高、及时性强的复杂挑战,GPT-5.5已经作念到了准确寄托。
这个节约到繁的测试标明,GPT-5.5在真正编程任务中,既能处理复杂逻辑与架构设想,也能精确反馈斥地者需求,且不轻松重构或引入其他代码,以至当我们条目回退到上一版块时,它也能领略规复到之前的气象。
03.
高幻觉率:能用,但不敢终结
尽管在实测中发扬惊艳,但团结公开数据来看,GPT-5.5已经莫得卓绝阛阓太大预期,而且存在不可淡薄的风险。
来看一组对比数据。
在Artificial Analysis的独到基准测试AA-Omniscience中,GPT-5.5的幻觉率高达86%,而Claude Opus 4.7仅为36%。这意味着在该测试所设定的、特意探伤模子学问领域的场景下,当GPT-5.5靠近不细主见谜底时,其“坦言不知”的概率远低于敌手,更倾向于生成一个可能差错的回话。
需要密致的是,这86%并不料味着模子在大大量日常问答中都会产生幻觉,而是其在触及学问盲区时的特定活动倾向。一位从业者解释,这可能是因为GPT-5.5的事实学问粉饰面更强,但不细目性也更过火进,关于不细主见问题会猜谜底。但在将其用于需要高可靠性的任务时,这一蓄意仍需引起高度警惕。
当GPT-5.5被部署到“自主职责”场景中时,这种高幻觉倾向可能会激励风险。

图源 / pexels
比如在数据分析与讲解生成任务中,它可能自信地援用不存在的数据、编造统计趋势,或基于差错事实建议决策建议,导致用户作念出偏离骨子的买卖判断。而在编程与调试关节,它提供的代码决策也许看起来合理,却可能无法运行,以至遁入安全时弊,大幅增多后期排查与树立的本钱。
而且,这类幻觉通常以高度自信、逻辑自洽的形势呈现。关于枯竭联系专科布景的用户而言,这种“细目性”输出极具骗取性,需要提高警惕。
除了技巧层面的隐忧,OpenAI这次的买卖计谋也显表现明确的意图:先用生态锁定用户,再用加价收割阛阓。
一方面,GPT-5.5首发时并未同步盛开API,仅限自家ChatGPT和Codex使用,初步将用户锁定在其愚弄生态内。另一方面,GPT-5.5的订价比较上一代有了显然高涨。凭据官方公布的数据,GPT-5.5每处理100万tokens,输入收费5好意思元,输出收费30好意思元。而上一代的GPT-5.4,输入和输出价钱分离为2.5好意思元和15好意思元,这意味着新一代的价钱平直翻了一倍。
要是与现时的主要竞争敌手对比,Anthropic最强的模子Opus 4.7订价为每百万tokens输入5好意思元、输出25好意思元。可以看出,GPT-5.5在输入价钱上与敌手抓平,但在输出价钱上则高出20%。
尽管OpenAI解释称,token使用成果的晋升可对冲价钱高涨,使用户骨子本钱无显然增多,但具体性价比仍需业界进一步考证。
关于这一模子,资深Agent从业者赵江杰评价谈,这次GPT-5.5的发布并未酿成断档最初,不如对社区热传的“Spud”模子预期的大幅晋升守望那么大,但在agentic和coding智商上仍然不息保抓头部顶尖位置,agentic智商晋升的同期也在推进基模厂商晋升模子迭代成果,OpenAI的下一代突破模子(GPT-6)很可能也在路上了。
总之,对平淡用户而言,GPT-5.5简略值得尝鲜,但不应视其为完全可靠的器具,对企业用户来说,在将其接入中枢职责流前开云体育官方网站,则必须肃肃,一朝出现那86%的“自信差错”,该由谁来兜底?
火狐中国官方网站入口 备案号:
备案号: