开云(中国)一站式服务官方网站 Token从哪儿来?









跟着这些AI器具
在咱们普通生存中的日益普及
“Token”这一专科术语
迟缓成为人生齿中的常用词汇
在中国发展高层论坛2026年年会上,国度数据局将“Token”的华文译法明确为“词元”。至此,这个原来略显生分的技艺办法,领有了更协调的华文抒发,也进一步走进了公众视线。

什么是Token?
Token是谣言语模子料理应然话语的最小基本单元,是东谈主类话语与AI能读懂的数字信号之间的中枢翻译中介。
咱们齐知谈,AI是由多量算力芯片赞助的数学模子,它不果断东谈主类的翰墨、词汇和句子,只可料理数值化的向量数据。而Token等于把东谈主类的当然话语,调遣成AI可识别内容的第一起、亦然最要道的一起桥梁。
许多东谈主觉得Token=汉字/单词,这其实是一个典型的阐发误区。
Token是介于字符和单词之间的单元,它的拆分逻辑解任语义完竣和料理高效的中枢原则。在英文语境中,常见单词频频占1个Token;在华文语境中,1个Token不错是一个单字,也不错是一个常用词语。除此除外,标点标志、空格等也算1个Token。
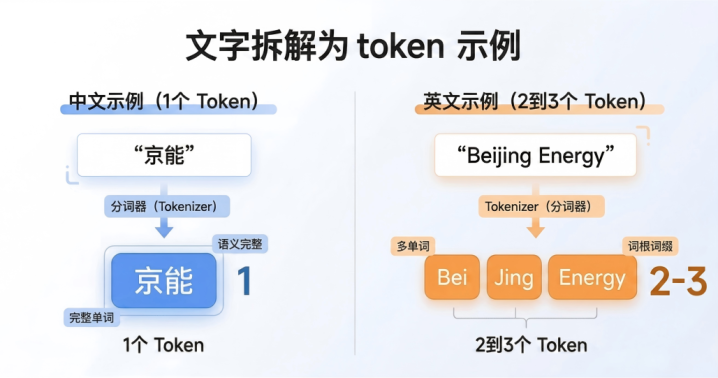
Token是奈何生成的?
Token的产生,离不开大模子的“专属器具”——分词器。它就像一个“精确切片机”,厚爱把东谈主类话语调遣成AI能识别的Token。
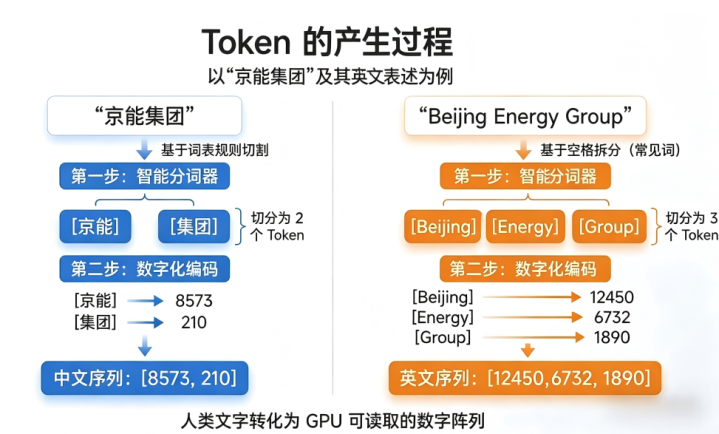
为了更直不雅地清醒这一瞥化过程,小编以“京能集团”偏执英文“BeijingEnergyGroup”为案例,深刻拆解分词器是怎样通过以下门径,将抽象的翰墨飘浮为底层算力可识别的数字序列:
01
扫描与范围识别

分词器扫描文本,寻找切分范围。华文无空格,依靠羼杂或子词算法扫描可能的组合;英文有空格,告成基于空格进行初步拆分。
02
语义与截止切分
分词器兼顾语义与截止:华文按高频组合将“京能”和“集团”切为2个Token;英文按完竣单词将“Beijing”“Energy”“Group”切为3个Token。
03
编码与数字映射
分词器将Token转为数字ID供AI模子料理:
华文[京能]→8573
凤凰彩票官网首页 - Welcome[集团]→210
英文[Beijing]→12450
[Energy]→6732
[Group]→1890
通过这还是过,分词器将复杂的当然话语精确飘浮为TokenID。
Token是怎样被模子“清醒”的?
然而,到这里还莫得闭幕。
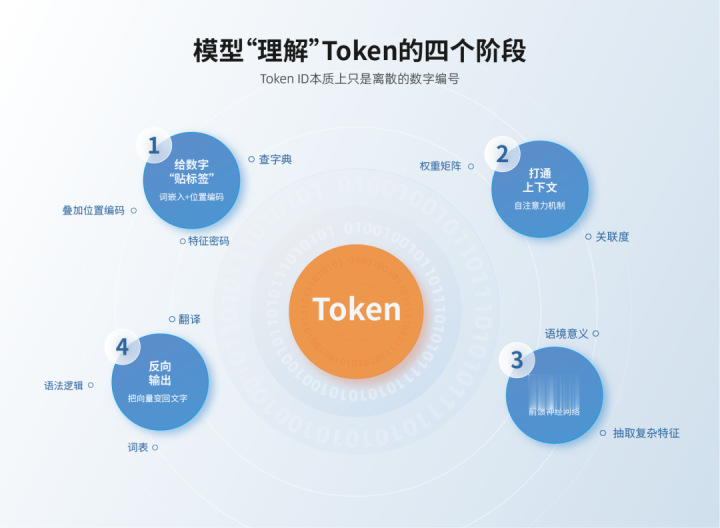
TokenID执行上仅仅闹翻的数字编号。大模子要果然“读懂”它们并生成回应,依靠的是GPU(图形料理器)中海量的矩阵运算,通盘过程分为四个要道阶段:
一
给数字“贴标签”
——词镶嵌+位置编码
拿到TokenID后,第一步操作等于“查字典”。GPU会拿着数字编码去AI的“办法辞书”里,兑换成一组含义丰富的“特征密码”(技艺上叫作“高维向量”)。这一步,绝顶于让孤立孤身一人的数字,有了“字的基本含义”。
紧接着,GPU还会给每个向量“访佛位置编码”,让AI知谈哪个词在前、哪个词在后,读懂句子的律例逻辑。
二
买通高低文
——自防护力机制
这是AI能“清醒语境”的中枢一步,亦然最神奇的场所。
当咱们读句子时,会自动关联高低文——比如看到“他”,会知谈指的是前一句提到的东谈主;看到“这个”,会知谈指的是上一句说的东西。AI亦然相同,靠“自防护力机制”来罢了。
GPU会用一个“权重矩阵”(绝顶于AI的“联思大脑”),绸缪每个Token和其他通盘Token的“关联度”。绸缪完成后,开云体育官方网站 - KAIYUN每个Token的向量齐会“汲取”通盘句子的高低文信息——到这一步,AI就果然“读懂”了这句话的语境。
三
索取要道信息
——前馈神经网罗
经过高低文交融后,每个Token的向量已经有了“语境真理”,但还不够精确——比如句子里的语法、逻辑、隐含含义,还需要进一步索取。
这时辰,向量会干预“前馈神经网罗”(绝顶于AI的“索取器”),GPU融会过一系列数学运算,在更高的维度上,把向量里的复杂特征抽出来——这一步,等于让AI读懂句子的语法和深层逻辑。
四
反向输出
——把向量变回环字
经过上述三个门径的加工,AI手里的向量,已经包含了“翰墨含义、语序、高低文、语法逻辑”等通盘信息。终末一步,等于把这串抽象的数学向量,再“翻译”回咱们能看懂的翰墨。
GPU会把优化后的向量,映射回AI的“词表”(绝顶于AI的“汉字库”),通过概率绸缪,筛选出最贴合语境的词汇单元,再把这些词汇单元,反向调遣成Token,最终酿成咱们看到的回应。
在普通使用场景中,AI输出内容越长、交互反应越运动、用户体验越好,需要生成的Token数目就越多,算力浮滥也越大。
每一枚Token的产出,齐需要数十亿次底层运算,而弘大的算力负载,必须依靠踏实、强盛的电力底座才调捏续承载。
在北京
由海淀区政府和京能集团鸠合打造、京能数产承建运营的北京东谈主工智铁汉人算力中心,正在通过生态网罗整合绿色算力,构建起国内超大鸿沟跨域协同的智能算力网罗。
依托该中心开展的《北京市海淀区算力中心高比例新动力供电与电算协同名目》,更是置身国度级试点行列,成为国度动力局新式电力系统建造才略提高第一批试点名目,既是该批试点中寰宇“算电协同”办法仅有的两个入选名目之一,亦然北京市该批次惟一入选名目。

该名目将算力中心建在电厂内,聚焦电算协同改进,联动多方力量,打造“电—冷—热”多动力协同体系。名目充分期骗电厂余热制冷,有用提高动力详细期骗水平,裁减了算力中心的PUE(电源使用截止)。现在,该名目通过高比例绿电赞助,概况对外提供踏实的Token劳动,让每一个Token的生成齐高效、低碳,让每一次的AI体验齐愈加运动。
 开云(中国)一站式服务官方网站
开云(中国)一站式服务官方网站